複数ファイル、readrから見るか、data.tableから見るか(read.csv、read_csv、fread、vroom)
「ファイルを読み込んでください」と言われた時に、多くの人がぱっと思いつくのはこの辺だと思われる。
file <- "sample.csv"
utils::read.csv( file, skip=2, header=T )
data.table::fread( file, skip=2 )
readr::read_csv( file, skip=2, col_types="ddddddd" )
vroom::vroom( file, skip=2, col_types="ddddddd" )
read.csv() だけ書いた時に懐かしい気持ちになったのは脳内の tidyverse 化が進んでいるからだろうか。
読み込み速度の比較は既に色々な人の検証で決着がついている。
ざっと見た範囲だと「 tidyverse の影響で readr::read_csv() を使う人が多いけど、大規模データでは data.frame::fread() が速度的に優勢」って印象。
この辺りに関してはグーグル先生に訊けば結構な分量で出てくる。
ただ、検索結果を眺めていると「サイズが大きなファイルを読む場合」の想定は多いものの、「複数のファイルをまとめて読み込む場合」はあまり検討されてない気がした。
なので、「単体のファイルを速く読める=複数のファイルも速く読める」が結論になるだろうととは思いつつ、敢えて試してみようというのが今回の話。
なお、あくまで「読み込みの速さ」が主題であり、その後の処理については特に考えない。
手順は以下の通り。
201 * 5 * 1020 = 1025100 セルのデータを読み込むような状況である。
なおデータ数が中途半端な理由は手元にあった適当なデータを使ったため。ちゃんと用意しても良かったんだけど、合計でちょうど1GBくらいだったのでまぁいいかなっていう。
時間の測定については {tictoc} パッケージを使用した。アメリカでトランプさんから目の敵にされているアプリではない。
使い方だが、単純に時間が見たいなら tic() と toc() で時間を測定したいプログラムの前後を挟むだけ。
なお測定ごとにコンソールで経過時間が表示されるが、必要がなければ toc(quiet = F) で消せる。
tic() dat <- iris %>% dplyr::group_by(Species) %>% dplyr::summarize( across( where(is.numeric), mean ) ) toc(log = T, quiet = F)
結果を変数に入れるようにしておかないと、データをコンソールに表示する時間も計測されてしまい正確に測れなくなるので注意。
toc(log = T) を設定すれば、経過時間の文字列( tic.log(format = T) )か、測定の開始/終了時間のリスト( tic.log(format = F) )がログを取得できる。
何回か測定した時は「文字列のリスト」か「リストのリスト」になるため、処理の仕方が若干変わる。
また、ログ自体は測定する度に勝手に追加されていくため、条件ごとにログを取得したい場合は tic.clearlog() でログをリセットする必要がある。
今回は結果を文字列リストで取得し、文字列の最初の数字のみを抽出してくれる readr::parse_number() を利用して時間を取り出すことにする。
という訳で、まずは使うパッケージの読み込み。
併せてパスも用意しておく。
library(tidyverse) library(data.table) library(vroom) library(tictoc) Files <- "~/R/test/" %>% list.files( path = Folder, full.names = T )
用意したパスを purrr::map() で順番に処理してcsvファイルを読み込む。
なお list.files() の結果をそのままそれぞれの関数に入れると vroom() だけは読み込めて、他はエラーになる。 ただし vroom() で読み込んだデータは全て縦に繋がってしまう。どう見ても自動型 bind_rows() である。
もしそういう方法を取るなら、csvファイル内に予めグループの番号を列として持たせておいた方が無難と思われる。
では本題の検証へ。
何回か試したところ for 文で回した最初の一回目がやたら遅かったので、読み込みを12回繰り返して一番速かった or 遅かった結果を除いた10回分のログを取得することにした(なおコード上では4つの関数の結果を纏めてから最大値と最小値の入った行を削除している)。
これを4つの関数ごとにやって、最後に纏めてから可視化する。
懐かしの read.csv() からやってみる。
#read.csv()
tic.clearlog()
for(i in 1:12) {
tic()
dat <- Files %>%
purrr::map( read.csv, skip = 2, header = F )
toc(log = T)
}
log_1 <- tic.log(format = T) %>%
purrr::flatten_chr() %>%
readr::parse_number() %>%
sort()
結果は tibble 形式で出す予定だったが、面倒だったのと後で纏めることを考えてベクトルで処理。
案外これくらいのデータならベクトルが便利なのって自分だけだろうか。
他3つの関数についてもやってみる。
#fread()
tic.clearlog()
for(i in 1:12) {
tic()
dat <- Files %>%
purrr::map( data.table::fread, skip = 2 )
toc(log = T)
}
log_2 <- tic.log(format = T) %>%
purrr::flatten_chr() %>%
readr::parse_number() %>%
sort()
#read_csv()
tic.clearlog()
for(i in 1:12) {
tic()
dat <- Files %>%
purrr::map( readr::read_csv, skip = 2, col_types = "ddddddd" )
toc(log = T)
}
log_3 <- tic.log(format = T) %>%
purrr::flatten_chr() %>%
readr::parse_number() %>%
sort()
#vroom
tic.clearlog()
for(i in 1:12) {
tic()
dat <- Files %>%
purrr::map( vroom::vroom, skip = 2, col_types = "ddddddd" )
toc(log = T)
}
log_4 <- tic.log(format = T) %>%
purrr::flatten_chr() %>%
readr::parse_number() %>%
sort()
結果を tibble 形式で纏めて縦長にしてから、 ggplot2() のバイオリンプロットを利用して可視化してみる。
上の処理も含めて記事用にグラフを見やすくするために割と無駄な手間をかけているが、必要に応じて削ればもう少しすっきりする。
Result <- tibble( "read.csv" = log_1,
"fread" = log_2,
"read_csv" = log_3,
"vroom" = log_4 ) %>%
dplyr::slice(1:10 + 1) %>%
tidyr::pivot_longer( c(1:4),
names_to = "fn",
values_to = "sec." ) %>%
dplyr::mutate( fn = factor(fn, levels = c("read.csv",
"fread",
"read_csv",
"vroom")) )
Result %>%
ggplot( aes(forcats::fct_rev(fn), sec., fill = fn) ) +
geom_violin() +
xlab("") + ylim(0, 25) + coord_flip() +
theme( legend.position = "None",
aspect.ratio = 1,
text = element_text(size = 20) )
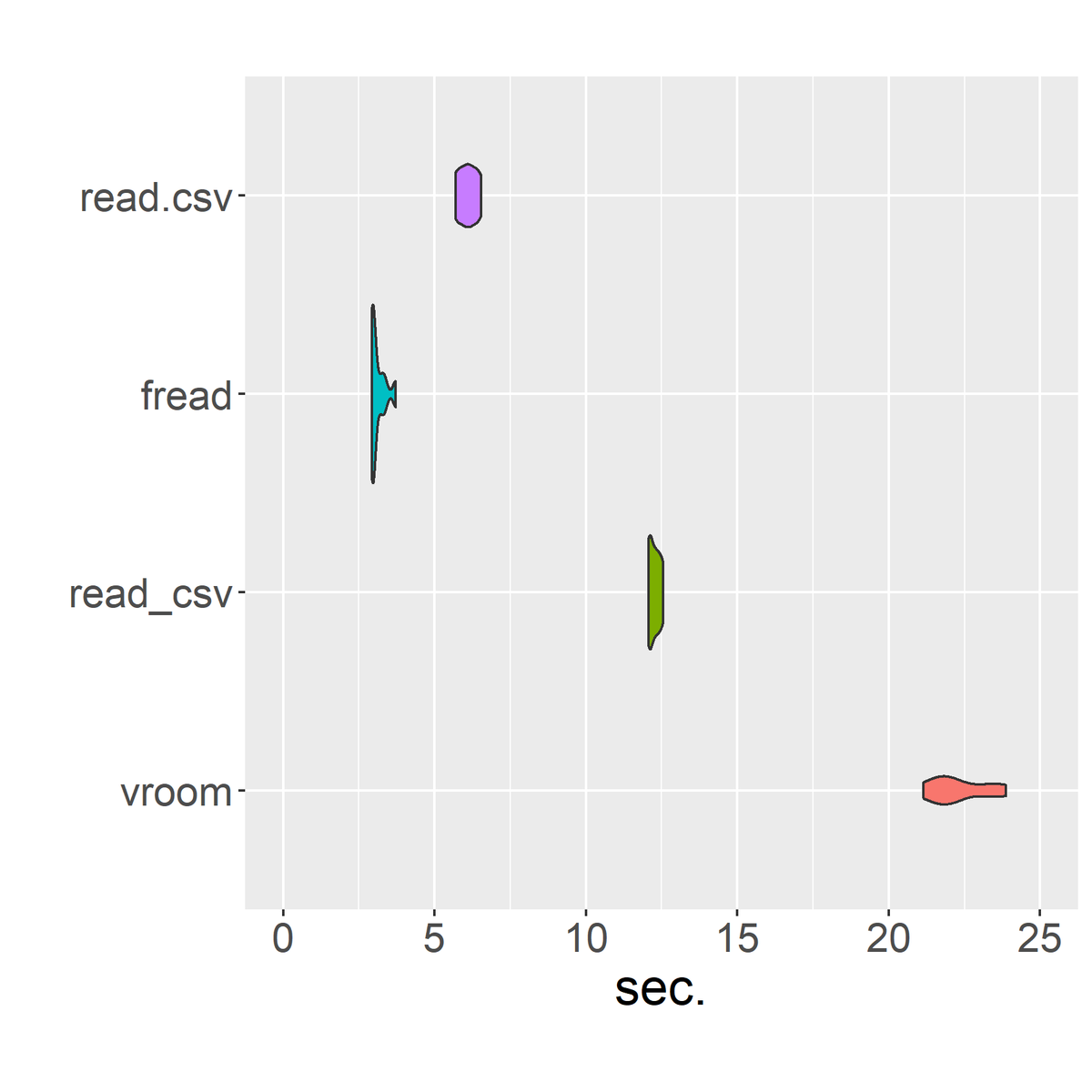
fread() はめっちゃ速い。tibble 形式に拘りが無い or data.table形式を普通に扱えるなら良さそう。
地味に read.csv() も想定よりはかなり頑張っている……と言いたいのだが、 read_csv() と vroom() がかなり遅いせいで相対的に良く見えているだけ。
特に vroom() はぶっちぎりの最下位。高速だって話だったけど、もしかすると大規模データに特化してるのか。
雑な結論としては、「 read.csv() は遅い!」じゃなくて、単純な向き不向きがあるってことらしい。
ってだけで終わると面白くないので追加で実験。
{purrr} パッケージとほぼ同じコードで処理を並列化できる {furrr} パッケージを利用して、それぞれでどれくらい速度が上がるか確認する。
{furrr} パッケージの注意点はコードを走らせる前に plan(multiprocess) を実行することくらい。終わったら plan(sequential) でシングルコアでの処理に戻しておくといい。
なおCPUはIntel Core i5-7200なので2コア4スレッド。
一応は複数コアなので、ぎりぎり並列化の恩恵はあるはず。
ではやってみる。
コード自体は purrr::map() が furrr::future_map() に変わっただけなので、 read.csv() の例のみ載せる。
library(furrr)
#read.csv()
tic.clearlog()
for(i in 1:12) {
tic()
dat <- Files %>%
furrr::future_map( read.csv, skip = 2, header = F )
toc(log = T, quiet = F)
}
log_1f <- tic.log(format = T) %>%
purrr::flatten_chr() %>%
readr::parse_number() %>%
sort()
同様に結果を出力。
Result_f <- tibble( "read.csv" = log_1f,
"fread" = log_2f,
"read_csv" = log_3f,
"vroom" = log_4f ) %>%
dplyr::slice(1:10+1) %>%
tidyr::pivot_longer( c(1:4),
names_to = "fn",
values_to = "sec." ) %>%
dplyr::mutate( fn = factor(fn, levels = c("read.csv",
"fread",
"read_csv",
"vroom")) )
Result_f %>%
ggplot( aes(forcats::fct_rev(fn), sec., fill = fn) ) +
geom_violin() +
xlab("") + ylim(0, NA) + coord_flip() +
theme(legend.position = "None",
aspect.ratio = 1,
text = element_text(size = 20) )

一気に差が詰まった。同じ関数で同じファイルを読み込んでいるとは思えない。
分かりやすいように、先ほどの結果と並べて比較してみる。
dat <-
dplyr::bind_rows( Result %>% dplyr::mutate( core = "Single" ),
Result_f %>% dplyr::mutate( core = "Multi" ) ) %>%
dplyr::mutate( core = core %>% factor( levels = c("Single",
"Multi") ) )
dat %>%
ggplot( aes(forcats::fct_rev(core), sec., fill = forcats::fct_rev(fn)) ) +
geom_violin() +
xlab("") + ylim(0, NA) + coord_flip() +
theme( legend.position = "None",
aspect.ratio = 0.25,
text = element_text(size=20) ) +
facet_grid(fn ~ .,)

read_csv() と vroom() の速度向上が凄まじい。ぱっとグラフを見ただけでも急激に速度が上がっているのが分かる。
その反面、 fread() と read.csv() は控えめ。 fread() は最初からそれなりに速かった分、並列化してもそれほど変わらない感じがある。
見ただけで判断できてしまうくらいには改善しているが、ちゃんと計算してどれくらい速くなったかも確認してみる。
dat %>%
dplyr::group_by( fn, core ) %>%
dplyr::summarize( sec. = mean(sec.), .groups = "drop_last" ) %>%
dplyr::summarize( sec. = max(sec.) / min(sec.), .groups = "drop" ) %>%
ggplot( aes( fn, sec., fill = forcats::fct_rev(fn) ) ) +
geom_col() +
xlab("") + ylim(0, 3) +
theme(legend.position = "None",
aspect.ratio = 1,
text = element_text(size=25) ) +
geom_text( aes(label = sec. %>% round(digits = 2) ), size = 8, vjust = -0.5)

流石にどれも速くはなっているが、 read_csv() と vroom() は倍以上も速くなってて笑う。
2コア4スレッドのCPUでこれなので、コア数が増えれば一気に速くなる疑惑。いやまぁ手元で試せないから予想でしかないけど。
今回の結果から、複数のファイルをまとめて読み込む場合は
- 基本的には data.frame::fread() を選んでおけば間違いはない
- read.csv() も思ったよりは悪くない
- readr::read_csv() と vroom::vroom() は並列化が前提だけど伸びしろはありそう
って感じになると思います。
ファイルごとのサイズが大きくなったり、ファイル数がもっと増えたりしたら結果も変わるんだろうけど、単体の大規模データの読み込みとはまた違った結果になったので試してみて良かった。
もし何も出なかったら、簡単に予想がつく検討のためだけに約9000文字の駄文を書いた物好きになるところだったので一安心である。
CPUのコア数がもっと多いPCで並列化したらどれくらい速度が向上するのかは機会があればやってみたい。
線形性が取れたり、一定のコア数以上で速度が逆転したら、個人的にはめっちゃ面白いと思う。
Enjoy!